Streaming 3D perception is well suited to robotics and augmented reality, where
long visual streams must be processed efficiently and consistently. Recent recurrent
models offer a promising solution by maintaining fixed-size states and enabling
linear-time inference, but they often suffer from drift accumulation and temporal
forgetting over long sequences due to the limited capacity of compressed latent
memories. We propose Mem3R, a streaming 3D reconstruction model with a
hybrid memory design that decouples camera tracking from geometric mapping
to improve temporal consistency over long sequences. For camera tracking,
Mem3R employs an implicit fast-weight memory implemented as a lightweight
Multi-Layer Perceptron updated via Test-Time Training. For geometric mapping,
Mem3R maintains an explicit token-based fixed-size state. Compared with CUT3R,
this design not only significantly improves long-sequence performance but also
reduces the model size from 793M to 644M parameters. Mem3R supports existing improved plug-and-play state update strategies developed for CUT3R.
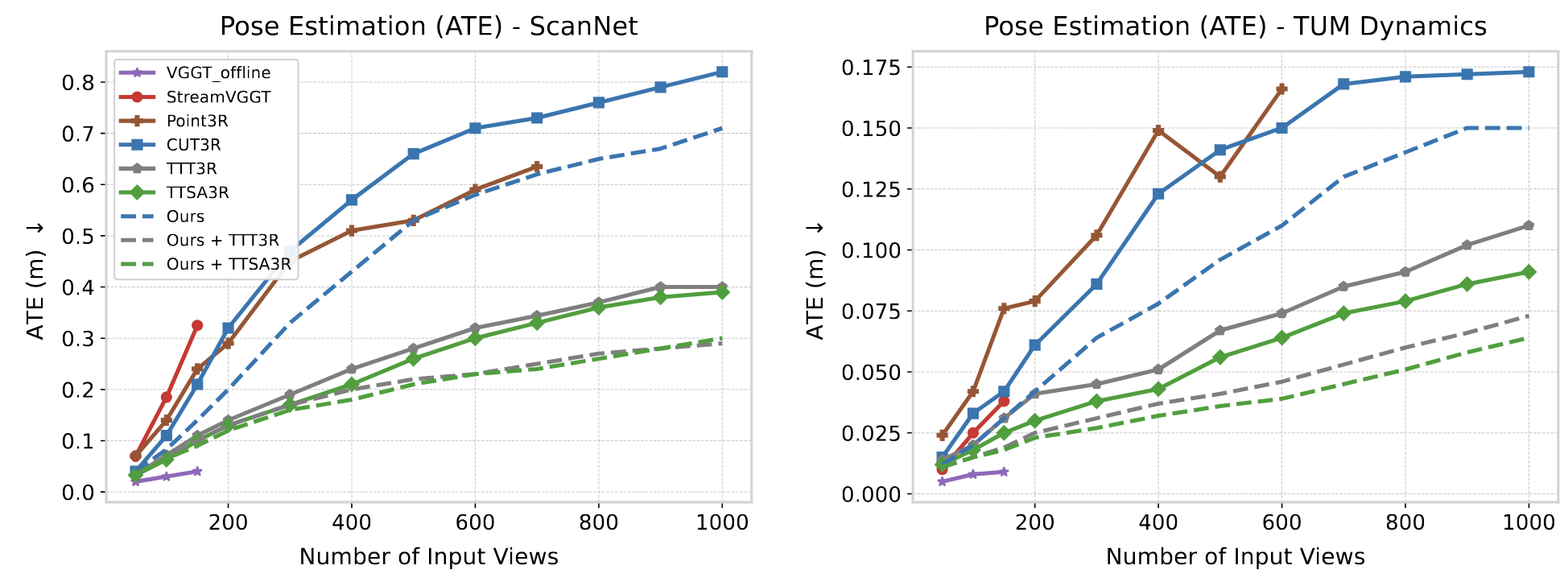
Specifically, integrating it with TTT3R decreases Absolute Trajectory Error
by up to 39% over the base implementation on 500 to 1000 frame sequences.
The resulting improvements also extend to other downstream tasks, including
video depth estimation and 3D reconstruction, while preserving constant GPU
memory usage and comparable inference throughput.